Claude Code y la síntesis de datos personales: enciclopedia de vida asistida por LLM
La integración de Claude 4 Sonnet con Claude Code permite ahora estructurar años de datos personales dispersos en una enciclopedia privada mediante el procesamiento de logs de ubicación y finanzas (Do

El Pitch
La integración de Claude 4 Sonnet con Claude Code permite ahora estructurar años de datos personales dispersos en una enciclopedia privada mediante el procesamiento de logs de ubicación y finanzas (Dossier UsedBy). La comunidad técnica debate si la utilidad de este "segundo cerebro" compensa el riesgo de privacidad que implica procesar toda tu vida a través de una API externa (HN).
Bajo el capó
El flujo de trabajo actual depende de las capacidades de razonamiento de Claude 4 Opus para sintetizar información, pero el proceso de ingesta es todavía rudimentario y manual. Los usuarios deben exportar activamente datos de Google Maps, Uber y sus entidades financieras para que el modelo pueda procesarlos (source: whoami.wiki). No existe una automatización nativa que elimine esta fricción inicial.
Claude ya tiene una tracción sólida en entornos de alta confianza con 247 usuarios de nivel corporativo registrados en nuestra base de datos, incluyendo a Notion y DuckDuckGo Ver ficha de Claude. Esta adopción por parte de entidades enfocadas en la privacidad sugiere que la infraestructura es robusta, aunque el uso de datos personales sensibles sigue siendo un punto crítico para los desarrolladores (Dossier UsedBy).
Existen debilidades estructurales en el output generado por el modelo:
- Sesgo editorial: Los usuarios tienden a omitir eventos negativos, creando una historia personal "limpia" pero poco veraz (fuente: HN Comment #5).
- Riesgo de seguridad: Enviar el historial de transacciones bancarias a una corporación estadounidense es una señal de alerta para cualquier dev consciente de la seguridad (fuente: HN Comment #4).
- Pérdida de valor artesanal: La automatización de la memoria familiar elimina el factor humano de la crónica histórica (fuente: HN Comment #1).
Aún no sabemos qué formato de almacenamiento local utiliza esta "enciclopedia" ni si Anthropic ofrece garantías específicas en 2026 sobre el no entrenamiento de modelos con estos archivos financieros (Dossier UsedBy).
La opinión de Diego
Es un experimento técnico brillante pero una pesadilla de privacidad para cualquier dev con dos dedos de frente. No voy a enviarle mi historial bancario y de ubicación a una corporación solo para que un LLM me resuma que gasto demasiado en café. Es una herramienta ideal para trastear en un side-project con datos sintéticos, pero para mi vida real, el coste de privacidad es inasumible. Si buscas una base de conocimientos técnica, usa Claude; si buscas un biógrafo, cómprate un diario.
Código limpio siempre,
Diego.
Diego Navarro - Early Adopter Tech Analyst at UsedBy.ai
Artículos relacionados
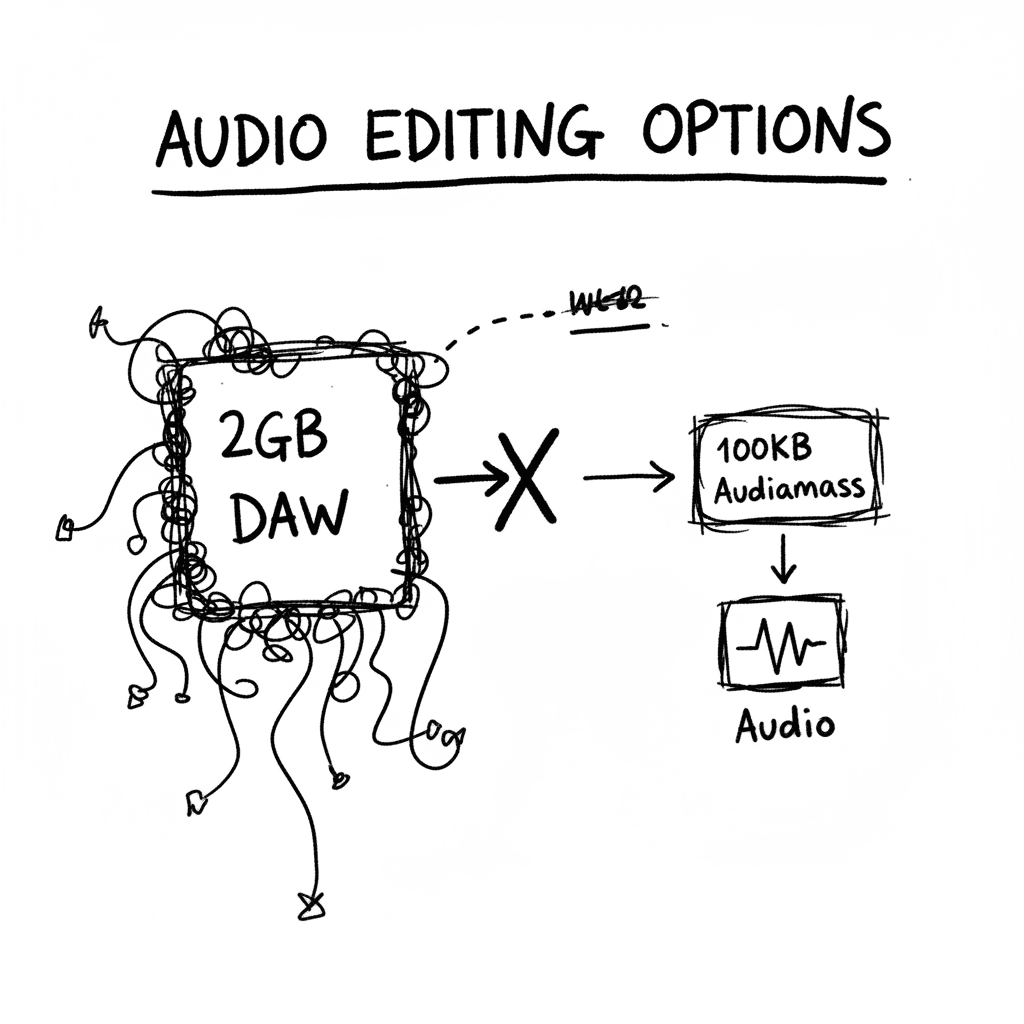
Audiomass: Edición de audio multitrack en 100KB de vanilla JS
Audiomass es un editor de audio basado en web que prescinde de backend y plugins, ejecutándose totalmente en el cliente mediante Web Audio API. En un 2026 saturado de aplicaciones pesadas, esta utilid
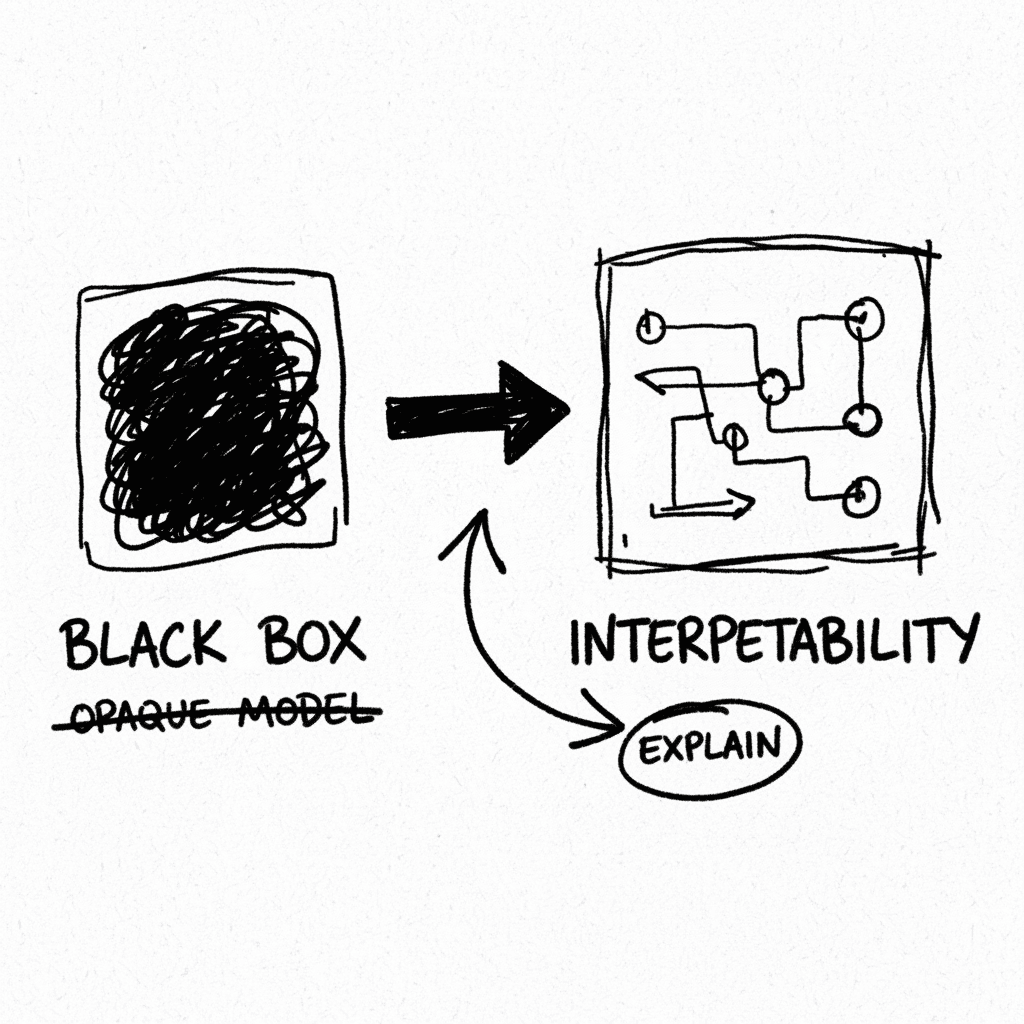
Protocolo Ético Magnifica Humanitas: La Interpretabilidad Mecanicista como Imperativo Moral
El documento establece que la tecnología nunca es neutral y que los ingenieros cargan con una responsabilidad directa sobre el impacto de sus arquitecturas. Basándose en la participación de figuras cl
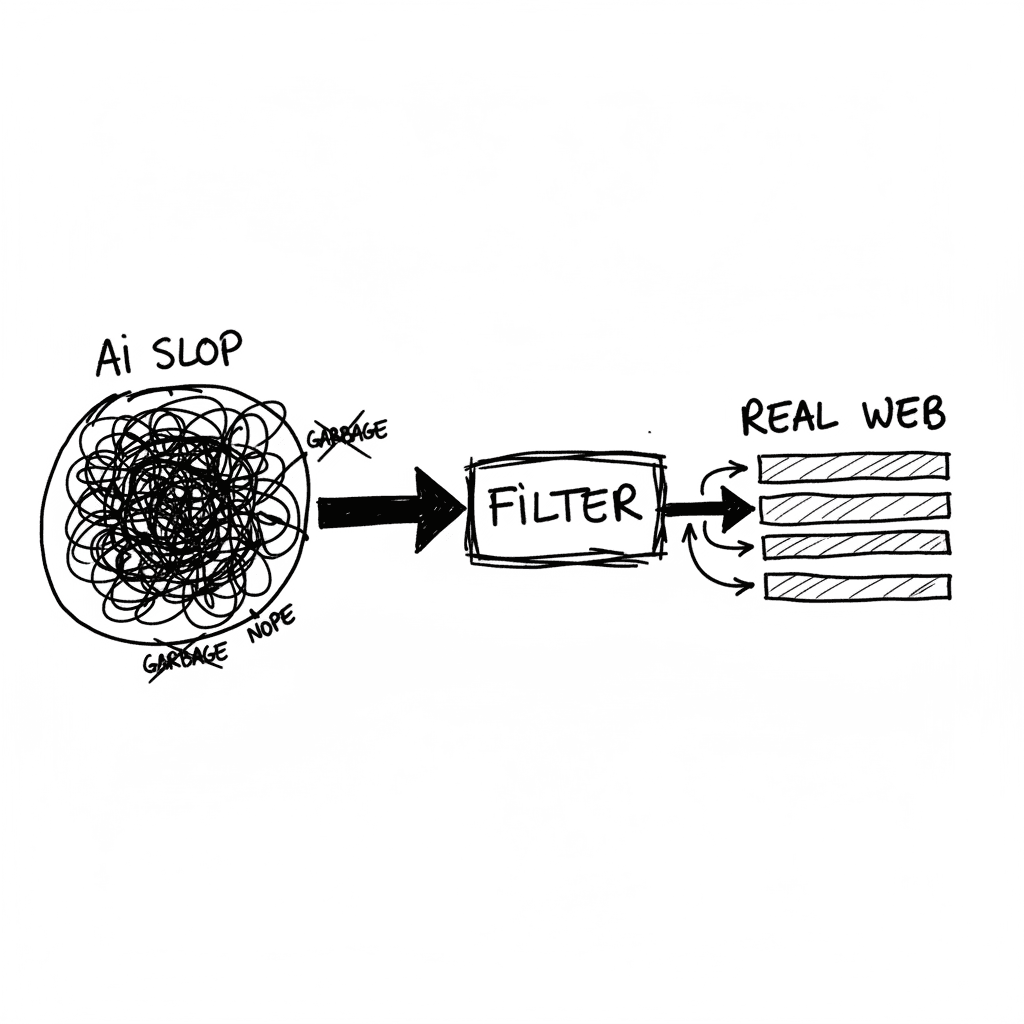
El estado de la búsqueda web en 2026: Kagi, Uruky y el modelo de suscripción
Google ha consolidado su transición de buscador a motor de respuestas con Gemini 3.5, capturando el 60% de las consultas sin que el usuario haga un solo clic (fuente: The Next Web). Ante este panorama
Mantente al día con las tendencias de adopción de IA
Recibe nuestros últimos informes y análisis en tu correo. Sin spam, solo datos.